

효율적인 MySQL 사용을 위해선 인덱스(index)가 필수다. 인덱스 지정에 따라 계산량이 얼마나 차이가 있는지 앞선 포스트에서 확인할 수 있다. 누구나 할 것같은 인덱스에 대해 조금 더 알아보자.
데이터베이스 서버의 입장에서 인덱스는 쿼리(Query)의 결과를 신속하게 전달해 줄 수 있는 중요한 기능이다. 인덱스가 없다면 데이터베이스는 모든 행을 검사해야 한다. 그럼 모든 테이블에 인덱스를 걸면 되지 않는가? ‘불가능하다’ 라고 단언할 수 있다. MySQL 은 ElasticSearch 등과 같은 검색엔진과 태생이 다르기 때문에 검색의 효율성은 그들에게는 2차적인 과제다.
MySQL 은 ‘인덱싱 데이터’를 별도의 유지 관리하고 있으며, 데이터가 변경될 때마다 이 데이터를 갱신해야 한다. 때문에, 테이블의 모든 컬럼에 인덱스를 쓰면 쓰기 속도가 저하되며, 물리적 저장소(Physical Storage)와 메모리 사용량이 급증하게 된다. 즉, CRUD 의 4개 요소에서 “R”이외의 다른 요소들은 극단적으로 성능이 저하되며 사용량 또한 증가한다.
부분 인덱스(Part Index)
성능을 향상시키고 싶지만, 용량 소비율을 최소화 할 때 주로 사용되는 방법으로, Field 전체보다 일부의 데이터만 인덱싱 하는 방법이다. 적잖은 사례에서 VARCHAR(255)를 사용하는 경우를 어렵지 않게 찾을 수 있는데, 실제 이 모든 크기를 사용하는 경우는 ‘확실히’ 드물기 때문. 보편적으로 접두사 부분 문자열에서 높은 엔트로피를 갖는다는 가정으로 특정 크기만큼의 인덱스를 지정하는 방법이다. (사실 VARCHAR(255)를 전체 인덱스하기는 쉽지 않다. 일반적으로 사용되는 InnoDB Storage Engine에서 전체 인덱스 키 크기가 767 바이트 이기 때문에 복합 인덱스 지정이 불가능 하다는 것. )
ALTER TABLE grip.news ADD INDEX (article_no (5));
위와 같이 크기(5)를 지정하는 경우 이 크기만큼만 색인하라는 의미이며, 이경우 데이터 사용량을 크게 줄일 수 있다. 현재 grip.news 에서 사용중인 WordPress 도 적잖은 Field 가 255 바이트로 지정되어 있다. 어떤 값이 들어올지 모르니, 최대한 크게 잡은 것.
멀티 컬럼 인덱스 (Multi Column Index)
복합 인덱스 또는 합성 인덱스라 부르기도 한다. 하나의 데이터 저장소에 2개 이상의 Field 색인을 저장한다. “그럼 개별로 두 개 이상의 인덱스를 지정하면 되는거 아닙니까!?” 라는 의문이 들 것이다. 안타깝게도, MySQL 은 단일 쿼리를 실행할 때 하나의 테이블 당 하나의 인덱스만 사용할 수 있다. 즉 article_no 와 category 를 별도의 인덱스로 선언하는 경우 MySQL 은 둘 중 인덱스싱된 데이터 내 행이 적은 것을 먼저 참고하게 된다.
따라서, 멀티 컬럼 인덱스를 사용하면 쿼리 속도를 향상시킬 수 있다. 제한되어 있는 인덱스 키 크기를 벗어 날 수 없기 때문에 빈번한 조합이 일어나는 Query 내 Field 를 지정하는 방법을 권장한다.
ALTER TABLE grip.news ADD INDEX idx_article_list (article_no, category);
고유 인덱스 (Unique Index)
레코드를 삽입하거나 갱신할 때 모든 값을 확인해 동일 값이 이미 존재하지 않는가를 확인한다. 유일한 값이므로 Primary Key 와 함께 사용되는 경우가 잦고, 조건절에서 명확히 언급하는 경우 가장 빠른 성능을 보인다. 엄연히 말해 고유 인덱스는 인덱스의 종류라기 보다는 ‘제약 조건’ 중 하나라 생각하는 것이 옳다.
ALTER TABLE grip.news ADD UNIQUE(article_no);
적절한 인덱스 사용 여부 확인
MySQL 에는 EXPLAIN 을 사용하면 SELECT Query 시 어떤 테이블에 인덱스를 추가해야 더 빠르게 레코드를 검색할 수 있는가 정보를 얻을 수 있다. EXPLAIN은 쿼리에 있는 테이블 하나당 한 행씩 출력되며, 결합된(JOIN/UNION등) SQL 에서는 두개의 행에 대한 결과를 얻을 수 있다. 자세한 정보는 MySQL 메뉴얼을 참조하자.
EXPLAIN SELECT article_no, category_name FROM grip.news JOIN grip.categorycode ON grip.news.catecory_code=grip.categorycode.catecory_code;
그리고 인덱스가 언제 동작하고 그렇지 않은지 알고 넘어가야 한다.
| 인덱스가 동작하는 경우 | 인덱스가 동작하지 않는 경우 |
|---|---|
|
|
인덱스 구조
인덱스 별 구조를 간단히 설명하면 다음과 같다.
- B Tree Index (Balanced Tree)
- 일반적으로 가장 많이 사용되는 형태
- 모든 경우에 유연하게 대처할 수 있어 전체적인 성능 균형이 잡혀있음
- Hash Index
- Balanced 다음으로 많이 사용 됨
- Tree와 Has Table이 비슷 한 경우 각 키에 Hash 함수를 실행하고 이를 일렬로 처리함.
- R Tree Index
- 공간 데이터 또는 N 차원 데이터를 처리할 때 사용됨 (일반적으로 거의 사용되지 않는다)
- 지도와 같이 3측 데이터의 응용 등에서 유용함
스토리지 엔진별 차이
MySQL 은 MyISAM 과 InnoDB 2개의 Storage Engine을 사용한다.
| MyISAM | InnoDB |
|---|---|
|
|
인덱스 현황 보기
동작중인 인덱스는 특별한 문제가 없다면 현황 자료를 볼 필요가 없지만, 테이블의 Query 가 느려지거나 명시적 인덱스에 문제가 발생하는 경우 어떤 컬럼에 인덱스가 동작하는지, 어떤 값이 존재하는지, 인덱스의 크기는 어느정도인지 같은 정보를 알 필요가 있다. SQL 은 매우 간단하다.
SHOW INDEXES FROM DATABASE.TABLE;
결과는 다음과 같다. (대부분의 버전에서 동일하다)
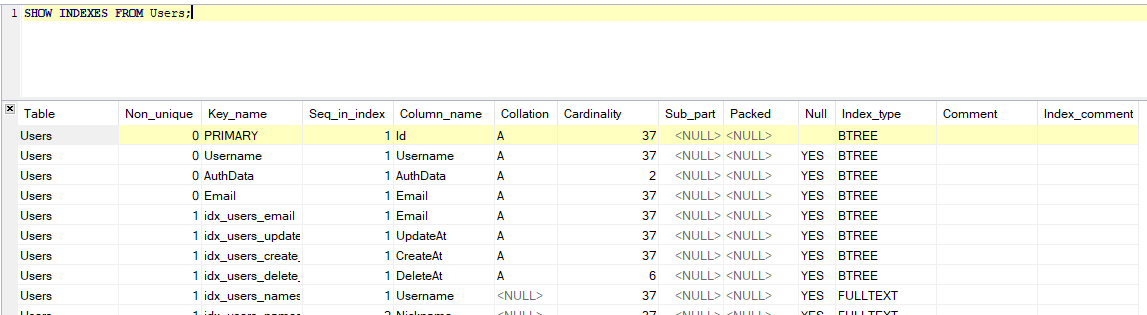

항목 별 내용은 다음과 같다. 특별한 부분은 없다.
| Table | 테이블 이름 |
|---|---|
| Non_unique | 제약조건에 Unique 가 선언되어 있는 경우 (유일한) |
| Key_name | 인덱스의 이름 |
| Seq_in_index | 인덱스의 컬럼 순서 |
| Column_name | 컬럼 이름 |
| Collation | 기본적인 정렬 형태. A:오름차순, NULL:정렬구분 없음 |
| Cardinality | 해당 인덱스 값의 Unique 값의 수. ANALYZE TABLE 또는 myisamchk -a를 사용해 업데이트 |
| Sub_part | Part Index인 경우 인덱스 된 문자 수. NULL 은 전체를 의미한다. |
| Packed | 키의 패키징 여부. 특별한 내용이 없을 경우 NULL 이다. |
| Null | NULL 포함 여부. YES = NULL 을 포함(허용) 한다. |
| Index_type | 인덱스 모드(BTREE, FULLTEXT, HASH, RTREE) / FULLTEXT 는 5.7 이상에서 유효 |
| Comment | 코맨트 |
| Index_comment | 인덱스 코맨트 |
통계 오류
서버에 발생한 어떤 이슈로 인해 잘못된 통계 자료를 기반으로 하는 경우 MySQL은 Query에 인덱스를 사용하지 않거나, 일부를 사용하는 등 이상행동을 보이게 된다. 이경우 Query에 일치하는 행의 수가 많다는 이유 만으로 인덱스를 사용하지 않고 테이블 스캔을 사용하는 이상 동작을 보이게 된다. 즉, 통계 오류가 발생하면 SQL 구문에 차이가 없지만, 성능이 저하되기 때문에 이유 없이 Slow Query 로 구분되는 경우가 발생하게 된다.
통계 재설정
앞선 오류 뿐만 아니라, 테이블의 잦은 변경이 가해짐으로서 인덱스의 ‘효율’ 이 나빠지는 문제가 생긴다. 오류가 아니라면, 다음과 같은 경우가 대부분이다.
- 물리 저장소(Physical Storage, HDD)의 단편화 (Fragmentation)
- 인덱스 통계의 부정확
이들 문제는 다음과 같은 방법으로 대응 할 수 있다.
| MyISAM | InnoDB |
|---|---|
|
|
※ 일반적으로 InnoDB 는 일정 주기가 지나면 통계 정보를 업데이트 하기 때문에 MyISAM 대비 오류 발생률이 상대적으로 적다.
대부분 개발자라면 알고 있는 내용이므로. 이정도로 정리.