



요즘 사내 메신저를 개발하다 보니 데이터 저장 및 활용에 대해 관심도가 그 어느때보다 높다. 메신저의 특징상 사용자에게 쾌적함을 주지 않는다면 단순히 강제하기란 쉽지 않다. 가장 고민거리는 ‘검색’이다. 단도직입적으로 내가 원천소스 부터 개발했다면 일찌감치 Solr 나 ElasticSearch 를 도입했을 것이다. 안타깝게도, ElasticSearch 와 연결하기 위한 Pipeline 이 끊어져 있고, 이를 오리지널 코드에 맞게 개발하는게 쉽지 않다는걸 수개월 걸친 삽질 끝에 깨달았다.
그럼 믿을 만한건 데이터베이스의 검색 능력이다. 우리가 사용하고 있는 MySQL 은 3년전 발표된 5.7에 InnoDB Storage Engine을 사용하면 Full-Text 검색 기능을 지원하고 있다. 5.7 이 GA(General Availability) 된 시점이 2015년 10월 인 만큼 거진 4년이 다 되어간다. 안타깝게도, AWS 의 RDS Serverless 는 현시점에서 MySQL 5.6 까지만 대응한다. 소식통을 살펴보면, 올해 가을 경 오레곤에서 테스트가 시작해 내년 경 5.7 이상이 반영될 예정이라고한다. (안타깝게도 AWS RDS MySQL 5.7은 n-gram 은 CJK 를 지원하나, Mecab 은 지원하지 않는다)

그런데 이쪽 시장을 담당하고 있는 사람들 조차 MySQL 의 Full-Text 검색에 대해 모르는 경우가 많아 의외였다. 이외에도 10년 전 부터 잘 사용하던 MySQL Memory Storage 도 모르는 사람도 꽤 되긴 하더라. (Redis 가 보편화 되기전 Cache 로 쓰기에 매우 유용했음에도 불구하고) 그리고, 오히려 나에게 MySQL 의 Full Text Search를 되묻는 사람들이 많았다. 그래서 간단히 정리해 보고자 한다.
MySQL 의 Full Text Search(이하 FTS)이란
한글은 단어의 끝맺음이 명확하지 않다. “I am SAM.”은 3개의 단어로 문장이 만들어져 있다. 한글로 만들면 “나는 지대공미사일 이다.” 이다. “나는” 은 “나”의 대명사와 “는”의 주격조사로 이뤄져 있다. MySQL 5.6 까지는 기본적으로 Full-Text Parser를 사용하고 있었기 때문에 단어가 명확히 끝이 명확하지 않기 때문에 Full-Text 인덱스를 사용하려고 하면 단어를 공백으로구분하거나 N-gram에서 분할 한 상태에서 DB에 저장하는 등의 조치가 필요했다. 즉, 꼬꼬마(ElasticSearch 기준에서는 최근 노리가 핫하니 Nori.)와 같은 형태소 분석기가 필요했다.
반면 MySQL 5.7 부터는 한글/일본어를 대응 할 수 있는 고도화된 Parser로 N-gram이 설치되어 있으며, MeCab (은전한닢)도 플러그인으로 사용할 수 있다. ElasticSearch 가 5.x 부터 은전한닢을 탑재할 수 있는 그런 느낌이랄까. 물론, FTS 자체가 없었던건 아니다. MySQL 5.5 이전에서는 MyISAM Storage Engine 에서 사용할 수 있었다. (1바이트 문자권 한정이지만.) MySQL 5.6 부터는 InnoDB 를 지원하게 되었지만 역시 2바이트 문자권 국가는 예외였다.
데이터형 대상
- CHAR
- VARCHAR
- TEXT
검색 문자열
- 단어의 조합
- 와일드카드 (*)
- BOOLEAN 타입 연산자 (+,-,~)
이 포스트는 가장 많이 사용되고 있는 MySQL 5.7을 기준으로 작성 됐다.
전체 텍스트 검색 기능 제한
MySQL 5.7 이후 FTS이 매우 유용해졌지만, ‘innodb_ft_result_cache_limit’ 에 대해 알고 있어야 한다. FTS에 있어 Thread 당 InnoDB FTS결과에 대한 Cache의 제한을 설정하는 것으로, 이 변수가 중요한건 InnoDB에서 FTS 결과가 메모리에서 처리 되기 때문이다. innodb_ft_result_cache_limit가 지나치게 될 경우 복수의 검색에 과도한 메모리가 소비되는 것을 막는다. 즉, 이 크기만큼을 Cache 로 보관 및 처리할 수 있는데 단위는 Byte 이고 최대 크기는 2^32-1 만큼 지정할 수 있다.
최근 시스템의 물리적 메모리가 커지기 때문에 이 Cache 를 적절히 잘 응용한다면 ElasticSearch 정도 까지는 아니더라도, 거의 필요성을 느끼지 않게 할 정도의 성능 향상을 가져올 수 있다. (5.6 이전이 그만큼 답답하다는 이야기)
테스트 환경 구축
MySQL 의 FTS를 테스트해보자. AWS는 RDS Instnace 에 5.7 이상을 제공하고 있지만, 사전 교체에 대한 문제가 있다. 때문에 EC2 Instance 에 MySQL 을 설치해 진행했다.
테스트 사양 정보
- EC2 Instance : t3.large(2vCPU, 8GB Memory)
- OS : Amazon Linux 2 (Linux kernel 4.14)
- DB : MySQL 5.7
STEP #1, MySQL Server 5.7 설치
Amazon Linux 는 기본적으로 MySQL 설치를 위한 패키지 정보가 없다. 5.7을 대상으로 할 예정이기에 5.7 을 설치했다. libpluginmecab.so 이 함께 설치되는걸 확인할 수 있다.
$ sudo wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm $ sudo yum localinstall mysql57-community-release-el7-11.noarch.rpm $ sudo yum install mysql-community-server $ systemctl start mysqld.service $ find /usr | grep libpluginmecab.so /usr/lib64/mysql/plugin/debug/libpluginmecab.so /usr/lib64/mysql/plugin/libpluginmecab.so # 초기 비밀번호 $ cat /var/log/mysqld.log | grep password 2019-05-20T01:32:56.381279Z 1 [Note] A temporary password is generated for root@localhost: <s0y&Qy4+p2p
기본적인 설정과 더불어 비밀번호 변경이 필요하다.
mysql> SET GLOBAL validate_password_length=8; Query OK, 0 rows affected (0.00 sec) mysql> SET GLOBAL validate_password_policy=LOW; Query OK, 0 rows affected (0.00 sec) mysql> ALTER USER root@localhost IDENTIFIED BY 'new password'; Query OK, 0 rows affected (0.00 sec) mysql> SHOW VARIABLES LIKE "chara%"; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec)
latin을 UTF 로 마저 변경하자.
$ vi /etc/my.cnf [mysqld] character-set-server=utf8 [client] default-character-set=utf8 $ systemctl restart mysqld.service mysql> SHOW VARIABLES LIKE "chara%"; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec)
STEP #2, mecab 설치
형태소 분석기를 설치한다. MySQL 과 마찮가지로 패캐지 설치를 지원하지 않기 때문에 소스를 받아 컴파일 해야 한다. 가장 최근 버전은 다음 URL 에서 확인할 수 있다.
- https://bitbucket.org/eunjeon/mecab-ko/downloads/
$ yum install gcc gcc-c++ $ cd /opt/ $ wget https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz $ tar xvfz mecab-0.996-ko-0.9.2.tar.gz $ cd mecab-0.996-ko-0.9.2/ $ ./configure --with-charset=utf8 $ make && make install $ ldconfig $ export PATH=$PATH:/usr/local/bin $ mecab -v mecab of 0.996/ko-0.9.2
만약, Ubuntu 의 경우 기본 사전이 함께 설치된다. 이경우 어떻게 형태소 분석이 되는지 살펴보면 다음과 같다. 한글 사전은 반드시 필요하다.
$ mecab 아버지가방에들어가신다. 아버지가방에들어가신다 特殊,記号,*,*,*,*,* . 特殊,記号,*,*,*,*,* EOS
STEP #3, 한글 사전 설치
잘 알려진 ‘은전한닢’ 사전을 설치하고자 한다. 은전한닢은 21세기 세종계획성과물을 사용하고 있고, 이용운님, 유영호님이 개발하고 계시다.
- 은전한닢 프로젝트 : http://eunjeon.blogspot.com
- 최신 사전 확인 : https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/
$ cd / $ sudo wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz $ sudo tar xvfz ./mecab-ko-dic-2.1.1-20180720.tar.gz $ sudo cd mecab-ko-dic-2.1.1-20180720 $ sudo ./configure $ sudo make $ sudo mecab -d . 아버지가방에들어가신다. 아버지 NNG,*,F,아버지,*,*,*,* 가 JKS,*,F,가,*,*,*,* 방 NNG,장소,T,방,*,*,*,* 에 JKB,*,F,에,*,*,*,* 들어가 VV,*,F,들어가,*,*,*,* 신다 EP+EF,*,F,신다,Inflect,EP,EF,시/EP/*+ᆫ다/EF/* . SF,*,*,*,*,*,*,* EOS
당연하지만, 의미 있는 데이터가 보인다.
| 기본사전 | 은전한닢 |
| 아버지가방에들어가신다. 아버지가방에들어가신다 特殊,記号,*,*,*,*,* . 特殊,記号,*,*,*,*,* EOS |
아버지가방에들어가신다. 아버지 NNG,*,F,아버지,*,*,*,* 가 JKS,*,F,가,*,*,*,* 방 NNG,장소,T,방,*,*,*,* 에 JKB,*,F,에,*,*,*,* 들어가 VV,*,F,들어가,*,*,*,* 신다 EP+EF,*,F,신다,Inflect,EP,EF,시/EP/*+ᆫ다/EF/* . SF,*,*,*,*,*,*,* EOS |
$ make install
STEP #4, MySQL Server 반영
MySQL 이 지금 설치한 한글 형태소 분석기를 사용할 수 있도록 도와줘야 한다. 사전 위치(loose-mecab-rc-file)를 알려주고, 단어의 최소 길이(innodb_ft_min_token_size)를 변경해야 한다. 그리고 MySQL 에 플러그인을 반영하면 된다.
# 사전 위치 변경하기 $ find /usr | grep mecabrc ./usr/lib64/mysql/mecab/etc/mecabrc ./usr/local/etc/mecabrc . . $ sudo vi ./usr/lib64/mysql/mecab/etc/mecabrc dicdir = /usr/local/lib/mecab/dic/mecab-ko-dic ; 사용자마다 다름 ## $ vi /etc/my.cnf [mysqld] loose-mecab-rc-file = /usr/lib64/mysql/mecab/etc/mecabrc innodb_ft_min_token_size = 1 $ mysql -uroot -p mysql> INSTALL PLUGIN mecab SONAME 'libpluginmecab.so'; Query OK, 0 rows affected (0.01 sec) mysql> SHOW PLUGINS; | ngram | ACTIVE | FTPARSER | NULL | GPL | | validate_password | ACTIVE | VALIDATE PASSWORD | validate_password.so | GPL | | mecab | ACTIVE | FTPARSER | libpluginmecab.so | GPL | +----------------------------+----------+--------------------+----------------------+---------+
마지막에 mecab 이 보인다. 이제 형태소 분석기 사용 준비가 완료됐다.
테스트
데이터만 있으면 바로 테스트 가능하다. 별도 주의사항은 없다. 단, 예제 데이터를 입력할 때 Engine 은 InnoDB를 선택해야 하고, 언어는 CHARSET 은 utf8 이어야 한다. 물론, 앞서 전역 설정을 변경했기 때문에 SQL 별다른 이상이 없다면 사전 정의된 대로 생성 및 삽입될 것이다.
- MySQL 5.7.26 기준
- innodb_ft_min_token_size 말고는 모두 기본값
테스트할 테이블을 만들 때 FULLTEXT 가 지정 되어 있어야 한다. 다음은 자사 테스트 데이터 기준으로 생성된 테이블 정보다. 단 FULLTEXT KEY 가 선언되어 있을 경우 그냥 데이터를 입력하느것 보다 더 많은 시간과 리소스를 필요로 하다. 운영중인 시스템에 반영할 경우 순간적으로 행이나 락이 걸릴 수 있기 때문에 주의해야한다.
만약 dump 된 데이터를 import 하는 경우 FULLTEXT 인덱스를 나중에 추가하자. import 단계에서사용하면 CPU 활용이 그리 좋지 않기 때문.
※ 정확한 시간을 측정한건 아니지만, 분석해야 하는 구문이 많을 수록 INSERT 에 많은 시간이 소요되었다. 긴 문장의 경우 5초 가까이 소요된 적도 있다.
mysql> SHOW CREATE TABLE M_GISATXT_3M\G
*************************** 1. row ***************************
Table: M_GISATXT_3M
Create Table: CREATE TABLE `M_GISATXT_3M` (
`M_IPT_ID` varchar(30) NOT NULL DEFAULT '',
`M_TXT` longtext,
PRIMARY KEY (`M_IPT_ID`),
FULLTEXT KEY `fulltext_idx` (`M_TXT`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> SHOW TABLE STATUS LIKE 'M_GISATXT_3M'\G
*************************** 1. row ***************************
Name: M_GISATXT_3M
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 713150
Avg_row_length: 2909
Data_length: 2075115520
Max_data_length: 0
Index_length: 36274176
Data_free: 4194304
Auto_increment: NULL
Create_time: 2019-05-20 06:24:24
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
만약 나중에 FULLTEXT 인덱스를 추가하려면 다음의 SQL 을 작성하면 된다.
mysql> ALTER TABLE table_name ADD FULLTEXT INDEX indexname(field) WITH PARSER ngram;
FULLTEXT 인덱스 확인
MySQL 5.7 의 기본 ngram_token_size 는 2 이기 때문에 2개의 문자를 기준(=bigram)으로 하며, 실제 인덱스 데이터에서 확인할 수 있다.
mysql> SET GLOBAL innodb_ft_aux_table = 'fts/M_GISATXT_3M';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE ORDER BY doc_id, position LIMIT 10;
+--------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+--------+--------------+-------------+-----------+--------+----------+
| su | 3 | 63578 | 15966 | 3 | 1 |
| ub | 3 | 64115 | 16076 | 3 | 2 |
| bt | 3 | 64952 | 16161 | 3 | 3 |
| tl | 3 | 64887 | 16155 | 3 | 6 |
| le | 3 | 59686 | 15326 | 3 | 7 |
| 12 | 3 | 71350 | 13271 | 3 | 11 |
| 2시 | 3 | 534894 | 14396 | 3 | 12 |
| 시용 | 3 | 924153 | 254 | 3 | 13 |
| 삼성 | 3 | 142974 | 8707 | 3 | 20 |
| 성생 | 3 | 931690 | 3981 | 3 | 23 |
+--------+--------------+-------------+-----------+--------+----------+
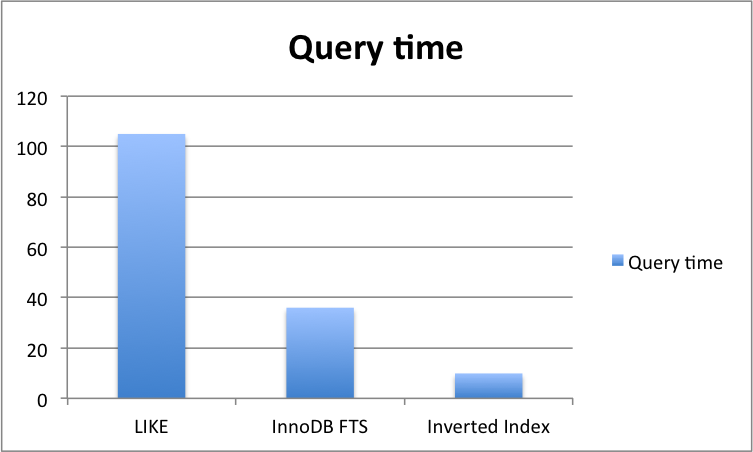
mysql> SELECT * FROM M_GISATXT_3M WHERE MATCH(M_TXT) AGAINST('서울' IN BOOLEAN MODE);
------------------------------------+
420436 rows in set (37.84 sec)
mysql> SELECT COUNT(*) FROM M_GISATXT_3M WHERE MATCH(M_TXT) AGAINST('서울' IN BOOLEAN MODE);
+----------+
| COUNT(*) |
+----------+
| 420436 |
+----------+
1 row in set (0.43 sec)
FTS가 반영되지 않은 테이블에서 ‘서울’ 글자가 있는 레코드가 몇개인지 찾아보자. 0.43 초와 5초. 10배(1,00%) 정도 차이가 난다.
mysql> SELECT COUNT(*) FROM M_GISATXT_3M WHERE M_TXT LIKE '%서울%'; +----------+ | COUNT(*) | +----------+ | 420436 | +----------+ 1 row in set (4.42 sec) mysql> SELECT COUNT(*) FROM M_GISATXT_3M WHERE M_TXT LIKE '%서울%'; +----------+ | COUNT(*) | +----------+ | 420436 | +----------+ 1 row in set (5.00 sec)
FTS 의 성능을 극단적으로 향상시킬려면 innodb_ft_result_cache_limit 를 향상시키면 된다.
mysql> SET GLOBAL innodb_ft_result_cache_limit=4000000000; Query OK, 0 rows affected (0.00 sec)
문제는 이 innodb_ft_result_cache_limit 에 있다. result_cache 의 최대값은 4GB 에 불과하다. 만약 n-gram 을 1개로 나누게 되면 도 많은 cache 를 필요로 하게 된다. 때문에 이 이상의 메모리를 필요로할지 모른다. 메모리 값은 많이 저렴해 졌다. 4GB 이상으로 설정하면 “FTS query exceeds result cache limit” 오류가 발생하며, 이 문제는 MySQL 8 에서도 동일하게 나타난다.

결론
MySQL Full Text Search 는 MySQL 의 ‘검색엔진’으로서 가능성을 보여주는 부분이다. 그 성능이 ElasticSearch 에 미치지는 못하나, 데이터의 개체수가 엄청나지 않다면 FTS 만으로도 충분히 원하는 결과를 얻을 수 있을거라 생각한다. 아직까지 많은 서비스들의 LIKE 검색에 의존하고 있음을 생각해봐야한다.
| 검색 성능이 크게 향상된다 | 더 많은 저장공간이 필요하 |
 |
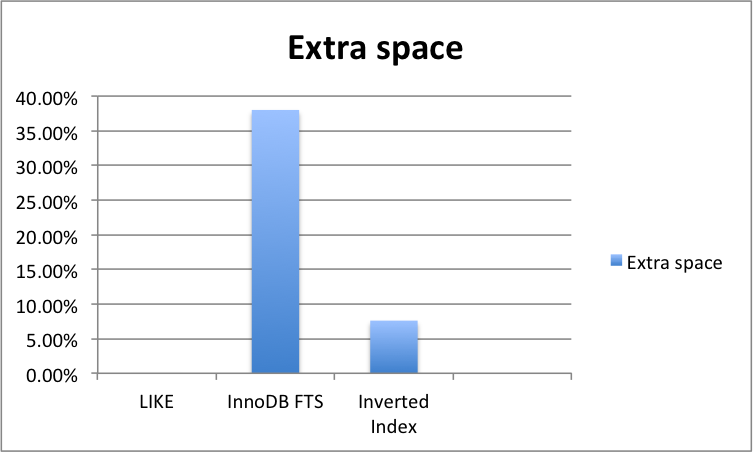 |

물론, FTS 가 장점만 있는건 아니다. 앞서 언급한 것과 같이 TEXT 처리부가 있기 때문에 전반적 Insert/Update 의 성능 저하가 발생한다. 인덱스 데이터를 저장해야 하기 때문에 Storage 사용량도 함께 증가한다. 더욱이 별도의 사전 데이터를 지정할 수 없는 AWS 에서는 있으나마나 한 가능일지도 모른다.
나라면, 당장 ElasticSearch나 Solar 를 써야할 정도로 규모가 갖춰진 서비스가 아니라면 서비스가 성장하기 전까지 MySQL 의 FTS 를 적극 응용할 듯.