

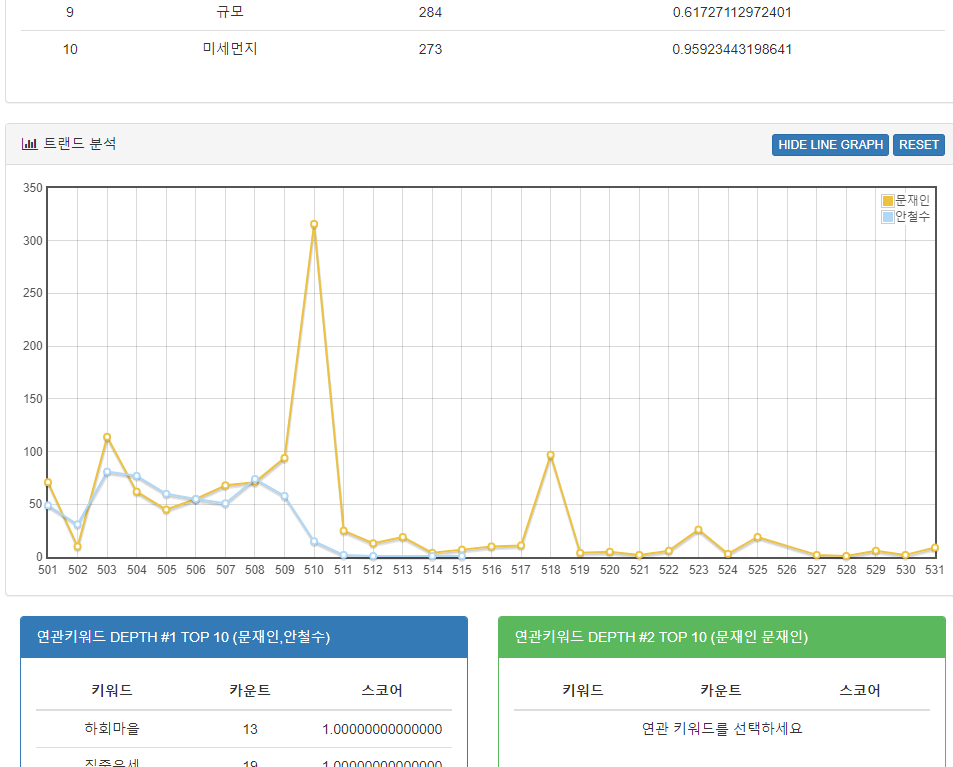
지난 2017년 자사 문서를 분석하기위한 문서 요약 플랫폼을 개발했다. 핵심 문서를 추출하게 되면 가중치 높은 단어를 찾을 수 있다. 그 단어가 그 문서의 핵심 키워드라 가정하고, 통계를 작성했다. 이 통계가 바로 ‘트랜드’다.
사람이 직접 입력한 것 만 못하지만, 대략 어떤 주제로 글이 작성 되었고 추세가 어떤지 알 수 있는 좋은 계기가 되었다.

EC2 Instance 로 구축했을 때 가장 큰 문제는 성능에 대한 유연한 대응이 불가능 했다는 점. (사실, 형태소 분석은 자체 워크스테이션을 갖춰 진행했다.) 그리고 늘 문제가 되는 문지 보수에 대한 이슈가 있었다. 이러한 단점은 Serverless 에서 어느정도 해결할 수 있다. 과연 이 프로젝트가 좋은 결과를 낳을지 자신은 없지만, (1) Lambda 에서 형태소 분석을 구현하고, (2) PageRank/LexRank 기반 문장 요약을 개발, (3) ElasticSearch 를 통해 검색을 가속하고자 한다.
이 포스트는 “(1) AWS Lambda 에서 형태소 분석을 구현 하는 방법“의 내용을 담고있다.
목표
가장 넓게 사용되는 범용 형태소 분석 엔진은 MeCab 이다. 오픈소스로 개발되고 있는 MeCab은 형태소 분석부터 검색 엔진에 응용 되는 등 반영되는 범위가 매우 넓다. ElasticSearch 도 노리(Nori)가 탑재되기 전까지 MeCab으 비공식 플러그인 형태로 지원했었다. 특히 Python 을 통한 다양한 예제들이 공개되어 있어 이 분야를 개발하려면 애초에 다른 언어를 선택하지 않는것이 좋다. 나중에 Tokenizer 개발단계에 진입하면 Python의 수많은 예제는 큰 도움이 된다.
이 포스트의 목적은 MeCab 과 사용자 사전을 Serverless 에 구현하는거다. MeCab은 Lambda 에, 용량이 큰 사용자 사전은 S3 에 등록하고, API Gateway 를 통해 형태소 분석 결과를 주고 받는데 있다. 자사에서 사용중인 고도화는 블로그에 담기 어려워 나중에 결과만 공유하고자 한다.
“형태소 분석” 만 생각해 보면 아키텍쳐는 매우 간단하다.

AWS 는 다양한 서비스를 제공하고 있다. 특히, AML(Amazon Machine Learning)을 사용하면 기존 데이터 패턴에서 모델을 만들어 새로운 데이터에 대한 예측된 결과를 얻을 수 있다. 물론 안타깝게도 (현 시점에서) AML 은 한글을 제대로 분석할 수 없어 Stand-alone 형태로 활용 가능성은 낮지만, 형태소 분석으로 의미 있는 값을 넣는다면 “작성자 + 키워드 + 시기 + 뉘앙스” 를 기준으로 작성될 것 같은 기사를 예측할 수 있다. 뿐만 아니라, 분위기에 맞는 글 추천도 가능하다. 짐작컨데, 워싱턴 포스트의 아크(ARC)의 추천 시스템이 AML 을 사용하고 있지 않을까.
구축
MeCab을 위한 Lambda 함수를 프로토타이핑 할 때 Node.JS 로 개발하는 경우 어떠한 플랫폼에서 개발해도 큰 지장이 없지만, 기본적으로 Python 과 가장 호흡이 잘 맞는다. 그리고 Linux 환경에서 개발하자. Lambda 에 파일을 등록해야 하는 절차에 동일 환경에서 빌드 되는것이 사이드 케이스 발생 확률을 낮춰준다. 이러한 이유에서 Linux 환경에서. 그리고 그중에서도 Amazon Linux 를 추천한다. Instance Type 은 최소 t3.small(2GiB) 이상을 선택하자. t3.micro(1GiB)는 메모리 문제로 인해 MeCab 이 이상동작하는 경우가 더러 있기 때문.
- t3.small, Amazon Linux 2 생성


Amazon Linux 필수 패키지 설치
환경 구축에 필요한 필수 패키지를 설치하자. gcc 는 MeCab을 빌드할때 사용하며, 은전한닢내 Python 예제를 갖고 오기 위해 git을 함께 설치했다.
$ sudo yum install -y gcc gcc-c++ git patch
※ 유용한 활용, Groonga : http://groonga.org/
Python 설치
제대로 개발할려면 아나콘다(Anaconda)가 필요하지만, 형태소 분석을 위해선 풀 패키지가 필요 하지 않다. 최소 설치 형태인 미니콘다(Miniconda)를 설치하고, 콘다 또는 pip 를 사용해 패키지를 확장하자. 미니콘다 버전 목록은 다음 repo 에서 확인할 수 있다. Python 은 2.7 / 3.7 어떤걸 선택해도 무관하나, Python 2.7 은 내년 1분기에 Fade-out 될 예정이기 때문에 되도록 최신 버전을 사용할 것을 권장한다.
- Miniconda : https://repo.continuum.io/miniconda/
$ sudo su $ wget --quiet https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3.sh $ chmod 755 ~/miniconda3.sh $ ~/miniconda3.sh -b -p $HOME/miniconda3 $ echo 'export PATH="$HOME/miniconda3/bin:$PATH"' >> ~/.bashrc $ source ~/.bashrc
MeCab 설치 및 사전 설치
범용 형태서 부석 엔진 MeCab 을 설치하자. 설치 내용은 은전한닢 프로젝트에서 확인할 수 있다. $NPD_SYNTAX 는 형태소 분석을 위한 프로젝트 폴더이다. MeCab의 설치는 복잡하지 않다.
- 은전한닢 : https://bitbucket.org/eunjeon/mecab-ko/downloads/
$ mkdir -p /opt/syntax && mkdir -p /opt/MeCab && cd /opt/MeCab $ export $NPD_SYNTAX=/opt/syntax $ wget https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz $ tar xvfz mecab-0.996-ko-0.9.2.tar.gz $ cd mecab-0.996-ko-0.9.2/ $ ./configure --with-charset=utf8 --enable-utf8-only --prefix=$NPD_SYNTAX/local $ make && make install $ cd $NPD_SYNTAX/local/bin $ ./mecab -v mecab of 0.996/ko-0.9.2
‘은전한닢’ 사전을 설치해야 한다. 은전한닢은 21세기 세종계획성과물을 사용하고 있고, 이용운님, 유영호님이 개발하고 계시다. 사전 설치 전에는 불가했던 형태소 분석이 비로소 가능하게 됐다.
- 최신 사전 확인 : https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/
$ cd /opt/MeCab $ wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz $ tar xvfz ./mecab-ko-dic-2.1.1-20180720.tar.gz $ export PATH=/opt/syntax/local/bin:$PATH $ export LD_LIBRARY_PATH=/opt/syntax/local/lib:$LD_LIBRARY_PATH $ ldconfig $ cd mecab-ko-dic-2.1.1-20180720 $ ./configure --prefix=/opt/syntax/local $ make && make install $ mecab 아버지가방에들어가신다. 아버지 NNG,*,F,아버지,*,*,*,* 가 JKS,*,F,가,*,*,*,* 방 NNG,장소,T,방,*,*,*,* 에 JKB,*,F,에,*,*,*,* 들어가 VV,*,F,들어가,*,*,*,* 신다 EP+EF,*,F,신다,Inflect,EP,EF,시/EP/*+ᆫ다/EF/* . SF,*,*,*,*,*,*,* EOS
Python 을 위한 MeCab을 설치하자. Python 2.7 을 사용할 경우 mecab-python 이 필요하다.
$ cd $NPD_SYNTAX $ pip install mecab-python3 -t .
스크립트 작성
가장 기본적인 Python 스크립트를 작성해 보자. 목적은 사전 경로를 지정하고, 특정 문장에 대해 형태소 분석이 가능한지 확인 하고자 한다. 유의해야 할 것은 Local 와 Lambda 에서 동작할 경우 환경 변수에 차이가 있다. (파일명 lambda_function 은 Lambda 에서 기본적으로 바인딩하는 명칭이며, 이 이름을 변경할 경우 Lambda 의 핸들러 설정을 변경해야 한다. lambda_handler도 같다. 특별한건 없지만 참고로만.)
$NPD_SYNTAX/lambda_function.py
# coding=utf-8
import os
import json
import MeCab
dicdir = os.path.join(os.getcwd(), 'local', 'lib', 'mecab', 'dic')
rcfile = os.path.join(os.getcwd(), 'local', 'etc', 'mecabrc')
def lambda_handler(event, context):
#sentence = event.get('sentence', '')
sentence = "아버지가방에들어가신다"
t = MeCab.Tagger('-d '+dicdir)
m = t.parseToNode(sentence)
while m:
print(m.surface, "\t", m.feature)
m = m.next
print("EOS")
이 스크립트의 특징은 ‘사전’을 Lambda 에 모두 업로드 한 것을 가정으로 하고 있고, 분석하고자 하는 구문을 포함하고 있다는 것이다. 중요한건 MeCab을 Lambda 에서 구현하는 것이고, 나머지는 부수적인 일이다. S3 사전 등록 및 응용은 다음 포스트에 작성할 예정이다. (여기까지는 오픈해도 괜찮을 듯하니) 이 스크립트를 로컬에 동작 시키기 위해 lambda_handler 를 강제 호출하고 실행해보자.
lambda_handler("", "") # 가장 하단에 추가 Lambda 에 등록하기 위해선 주석처리가 필요하다
.
.
$ python lambda_function.py
BOS/EOS,*,*,*,*,*,*,*
아버지 NNG,*,F,아버지,*,*,*,*
가 JKS,*,F,가,*,*,*,*
방 NNG,장소,T,방,*,*,*,*
에 JKB,*,F,에,*,*,*,*
들어가 VV,*,F,들어가,*,*,*,*
신다 EP+EC,*,F,신다,Inflect,EP,EC,시/EP/*+ㄴ다/EC/*
BOS/EOS,*,*,*,*,*,*,*
EOS
AWS Lambda 스크립트 등록
MeCab 패키지와 lambda_function.py 를 Lambda 에 업로드 하자. 기본적으로 업로드 되어야 하는 폴더 구조는 다음과 같다.
$ tree -d -L 2
.
├── bin
├── env
│ ├── bin
│ ├── include
│ └── lib
├── etc
├── include
├── lib
│ └── python3.7
├── libexec
│ └── mecab
├── local
│ ├── etc
│ └── lib
├── MeCab
│ ├── dic
│ └── __pycache__
└── share
└── man
FTP 처럼 파일을 드래그&드롭해 등록하면 좋겠지만 아직 지원하고 있지 않으며, ZIP 파일 형태로 업로드 해야 한다. Lambda 에 파일을 등록할 때 왜 이게 실행되지 않지? 라고 한다면 다음 조건을 충족하지 못했기 때문이다.
물론 zip 파일을 생성하면 위에 폴더처럼 깔끔하게 저장되지 않는다. pip 로 설치하면 사용에 불필요한 정보들이 함께 설치되기 때문인데, 이들을 배제하기 위한 exclude.lst 파일을 만들자. .gitignore 같은 역할을 한다 생각하면 이해하기 편하다.
$ cat exclude.lst *.dist-info/* *.egg-info *.pyc env/* exclude.lst lambda_function.zip
이제 압축파일을 만들자. 압축된 파일은 사전을 포함하고 있기 때문에 매우 거.대. 하다. 51MB(49.2MiB)..
$ cd $NPD_SYNTAX $ zip -r9 ./lambda_function.zip * -x@exclude.lst . . 51539678 Jul 10 01:49 lambda_function.zip
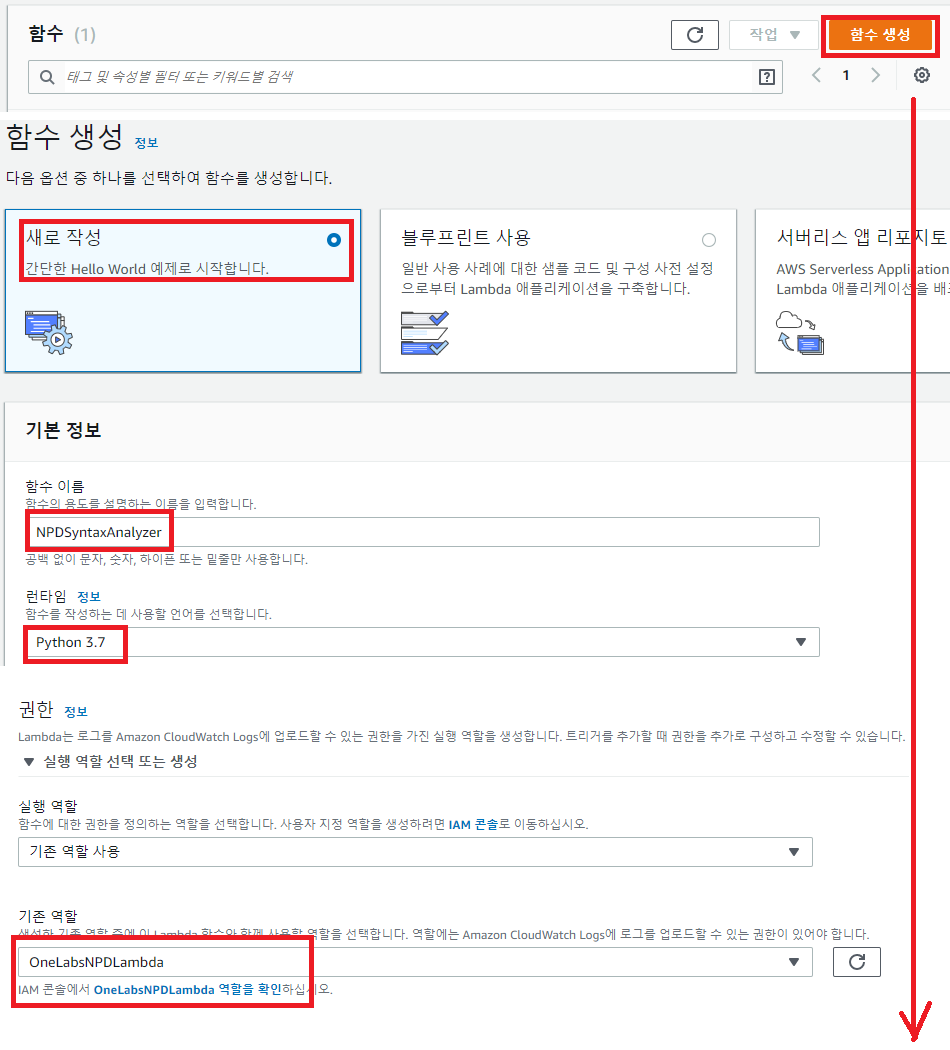
Lambda 함수 생성 및 업로드
처음 다루는 사람이라면 어려울 부분은 없다. 처음 다루는 사람이라면 ‘역할’ 부분을 고려해야 하며, 사용할 역할에는 CloudWatch Logs 와 Lambda Execute, VPC Access 권한이 반드시 필요하다. CloudWatch Logs 는 Lambda 의 로그를 기록해 줄 것이며, Lambda Execute 는 실행 권한을, VPC Access 는 추후 외부 통신을 위해 필요하다.

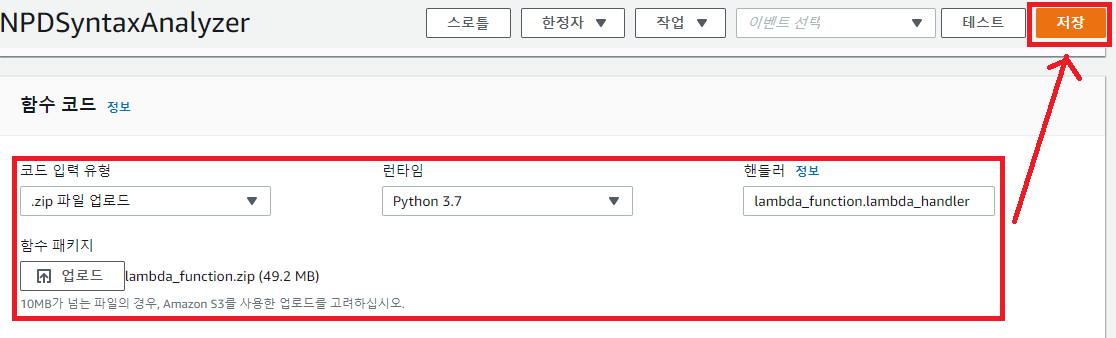
생성된 Lambda 에 앞서 압축한 lambda_function.zip 을 업로드하자. 10MB 이상의 파일은 S3 에 등록을 권장하지만, 한국의 뛰어난 인터넷 환경은 높은 신뢰도를 제공하기 때문에 … 본인 경험상 문제가 된 적은 없다. (1XX MB 단위도 문제가 된 적 없다. 필자도 처음에는 꼬박꼬박 S3에 등록 후 실행했지만 그럴 필요가 없다는걸 이후 ..)
여기서 주의해야 할 부분은 “핸들러” 설정이다. 핸들러 명칭은 “스크립트이름.핸들러함수”다. 앞서 만든 Python 스크립트 명칭은 lambda_function.py 이고, lambda_handler 함수를 갖고 있다. (확장자는 빼야함)

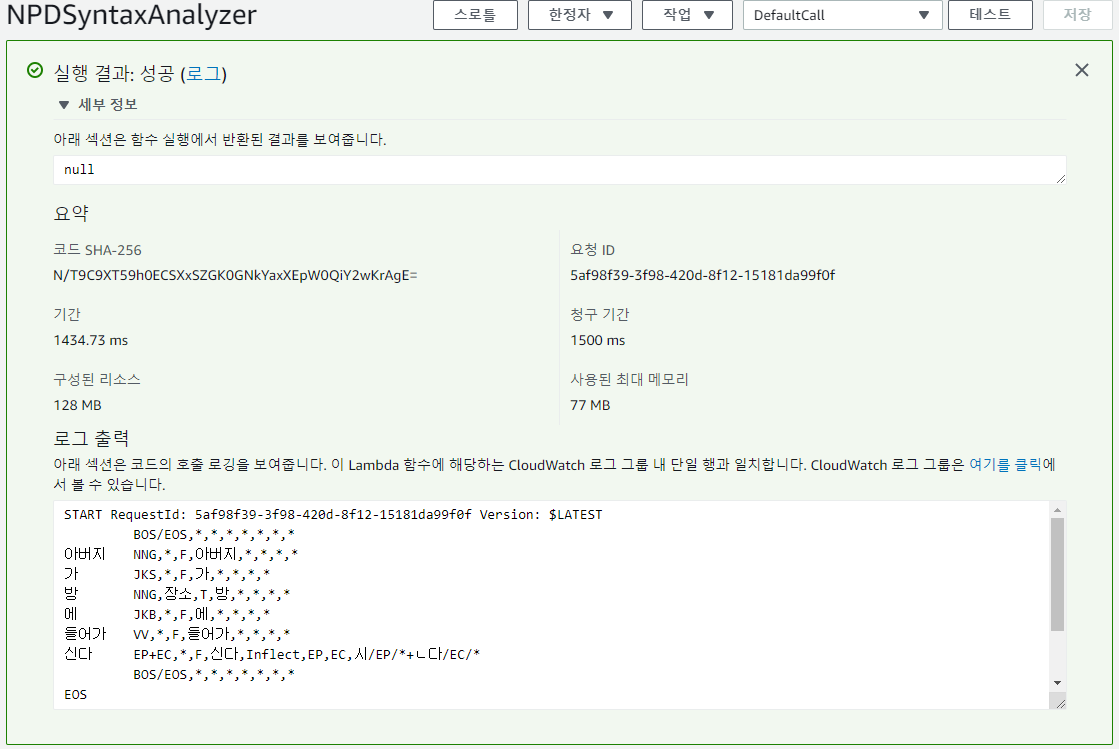
업로드가 완료되었으면 기본적인 테스트 항목을 만들자.
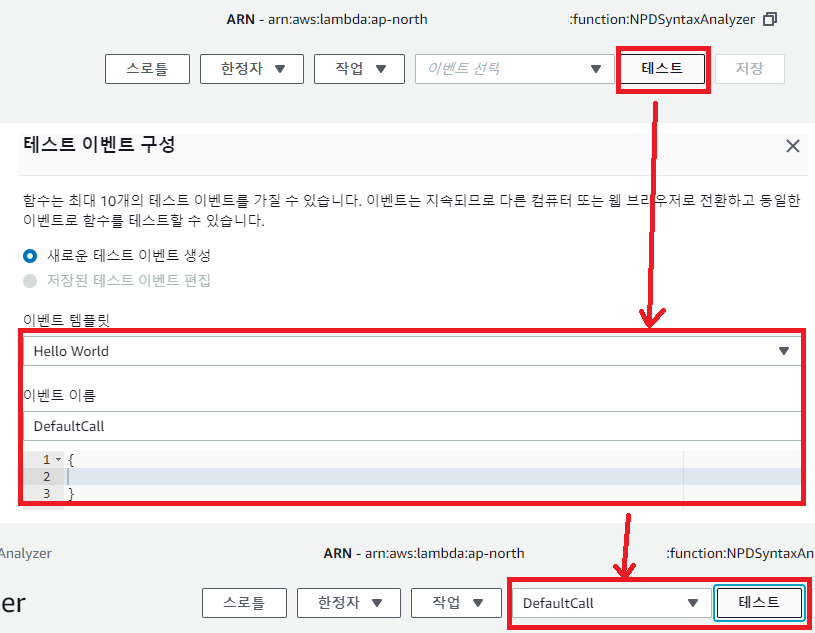

테스트 버튼을 누르면? 결과를 로그 출력부에서 확인할 수 있고, 자세한 내용은 CloudWatch 에서 확인할 수 있다.

결론
MeCab을 AWS Lambda 에 올리는 작업은 매우 간단하다. 구문 분석 및 활용을 위한 구축이 완료 된 것. 이제 순차적으로. 고도화 해 보자.